Artificial Intelligence
Naturally, AI plays a central role in every AIoT initiative. If this is not the case, then it is maybe IoT - but not AIoT. In order to get the AI part right, the Digital Playbook proposes to start with the definition of the AI-enabled value proposition in the context of the larger IoT system. Next, the AI approach should be fleshed out in more detail. Before starting the implementation, one will have to also address skills, resources and organizational aspects. Next, data acquisition and AI platform selection are on the agenda before actually designing and testing the model and then building and integrating the AI Microservices. Establishing MLops is another key prerequisite for enabling an agile approach, which should include PoC, MVP and continuous AI improvements.
Understanding the Bigger Picture
Many AIoT initiatives initially only have a vague idea about the use cases and how they can be supported by AI. It is important that this is clarified in the early stages. The team must identify and flesh out the key use cases (including KPIs) and how they are supported by AIoT. Next, one should identify what kind of analysis or forecasting is required to support these KPIs. Based on this, potential sensors can be identified to serve as the main data source. In addition, the AIoT system architecture must be defined. Both will have implications for the type of AI/ML that can be applied.

The AIoT Magic Triangle
The AIoT Magic Triangle describes the three main driving forces of a typical AIoT solution:
- IoT Sensors & data sources: What sensors can be used, taking physical constraints, cost and availability into consideration? What does this mean for the type of sensor data/measurements which will be available? What other data sources can be accessed? And how can relevant data sets be created?
- AIoT system architecture: How does the overall architecture look like, e.g. how to distributed data and processing logic between cloud and edge? What kind of data management and AI processing infrastructure can be used?
- AI algorithm: Finally, which AI method/algorithm can be used, based on the available data and selected system architecture?
The AIoT magic triangle also looks at the main factors that influence these three important factors:
- Business requirements/KPIs, e.g., required classification accuracy
- UX requirements, e.g., expected response times
- Technical/physical constraints, e.g., bandwidth and latency

The AIoT magic triangle is definitely important for anybody working on the AIoT short tail (i.e., products), where there are different options for defining any of the tree elements of the triangle. For projects focusing on the AIoT long tail, the triangle might be less relevant - simply because for AIoT long tail scenarios, the available sensor and data sources are often predefined, as is the architecture into which the new solutions have to fit. Keep in mind that the AIoT long tail usually involves multiple, lower-impact AIoT solutions that share a common platform or environment, so freedom of choice might be limited.
Managing the AIoT Magic Triangle
As a product/project manager, managing the AIoT magic triangle can be very challenging. The problem is that the three main elements have very different lifecycle requirements in terms of stability and changeability:
- The IoT sensor design/selection must be frozen earlier in the lifecycle, since the sensor nodes will have to be sourced/manufactured/assembled - which means potentially long lead times
- The AIoT System Architecture must usually also be frozen some time later, since a stable platform will be required at some point in time to support development and productization
- The AI Method will also have to be fixed at some point in time, while the actual AI model is likely to continuously change and evolve. Therefore, it is vital that the AIoT System Architecture supports remote monitoring and updates of AI models deployed to assets in the field
The diagram following shows the typical evolution of the AIoT magic triangle in the time leading up to the launch of the system (including the potential Start of Production of the required hardware).

Especially in the early phase of an AIoT project, it is important that all three angles of the AIoT magic triangle are tried out and brought together. A Proof-of-Concept or even a more thorough pilot project should be executed successfully before the next stages are addressed, where the elements of the magic triangle are frozen from a design spec point of view, step by step.
First: Project Blueprint
Establishing a solid project blueprint as early as possible in the project will help align all stakeholders and ensure that all are working toward a common goal. The project blueprint should include an initial system design, as well as a strategy for training data acquisition. A proof-of-concept will help validate the project blueprint.
Proof-of-Concept
In the early stages of the evaluation, it is common to implement a Proof-of-Concept (PoC). The PoC should provide evidence that the chosen AIoT system design is technically feasible and supports the business goals. This PoC is not to be confused with the MVP (Minimal Viable Product). For an AIoT solution or product, the PoC must identify the most suitable combination of sensors and data sources, AI algorithms, and AIoT system architecture. Initially, the PoC will usually rely on very restricted data sets for initial model training and testing. These initial data sets will be acquired through the selected sensors and data sources in a lab setting. Once the team is happy that it has found a good system design, more elaborate data sets can be acquired through additional lab test scenarios or even initial field tests.
Initial System Design
After the PoC is completed successfully, the resulting system architecture should be documented and communicated with all relevant stakeholders. The system architecture must cover all three aspects of the AIoT magic triangle: sensors and data selection, AIoT architecture, and AI algorithm. As the project goes from PoC to MVP, all the assumptions have to be validated and frozen over time, so that the initial MVP can be released. Depending on the requirements of the project (first-time-right vs. continuous improvement), the system architecture might change again after the release of the MVP.
It should be noted that changes to a system design always come at a cost. This cost will be higher the further the project is advanced. Changing a sensor spec after procurement contracts have been signed will come at a cost. Changing the design of any hardware component after the launch of the MVP will cause issues, potentially forcing existing customers to upgrade at extra cost. This is why a well-validated and stable system architecture is worth a lot. If continuous improvement is an essential part of the business plan, then the system architecture will have to be designed to support this. For example, by providing means for monitoring AI model performance in the field, allowing for continuous model retraining and redeployment, and so on.
Define Strategy for Training Data Acquisition and Testing
In many AI projects, the acquisition of data for model training and testing is one of the most critical - and probably one of the most costly - project functions. This is why it is important to define the strategy for training data acquisition early on. There will usually be a strong dependency between system design and training data acquisition:
- Training data acquisition will rely on the system architecture, e.g., sensor selection. The same sensor, which is defined by the system architecture, will also have to be used for the acquisition of the training data.
- The system architecture will have to support training data acquisition. Ideally, the systems used for training data acquisition should be the same system, which is later put into production. Once the system is launched, the production system can often be used to acquire even more data for training and testing.
Training data acquisition usually evolves alongside the system design - both are going hand in hand. In the early stages, the PoC environment is used to generate basic training data in a simple lab setup. In later stages, more mature system prototypes are deployed in the field, where they can generate even better and more realistic training data, covering an increasing number of real-world cases. Finally, if feasible, the production system can generate even more data from an entire production fleet.
Advanced organizations are using the so-called "shadow mode" to test model improvements in production. In this mode, the new ML model is deployed alongside the production model. Both models are given the same data. The outputs of the new model are recorded but not actively used by the production system. This is a safe way of testing new models against real-world data, without exposing the production system to untested functionality. Again, methods such as the "shadow mode" must be supported by the system design, which is why all of this must go hand in hand.
Second: Freeze IoT Sensor Selection
The selection of suitable IoT Sensors can be a complex task, including business, functional and technical considerations. Especially in the early phase of the project, the sensor selection process will have to be closely aligned with the other two elements of the AIoT magic triangle to allow room for experimentation. The following summarizes some of the factors that must be weighted for sensor selection, before making the final decision:
- Functional feasibility: does the sensor deliver the right data?
- Response speed: does it capture time-sensitive events at the right speed?
- Sensing range: does it cover the required sensing range?
- Repetition accuracy: does it tread similar events equally?
- Adaptability: can the sensor be configured as required, are all required interfaces openly accessible?
- Form factor: Size, shape, mounting type
- Suitability for target environment: ruggedness, protection class, temperature sensitivity
- Power supply: voltage range, power consumption, electrical connection
- Cost: What is the cost for sensor acquisition? What about additional operations costs (direct and indirect)?
Of course, sensor selection cannot be performed in isolation. Especially in the early phase, it is important that sensor candidates be tested in combination with potential AI methods. However, once the team is convinced on the PoC-level (Proof of Concept) that a specific combination of sensors, AI architecture and AI method is working, the decision for the sensor is the first one that must be frozen, since the acquisition of the sensors will have the longest lead time. Additionally, once this decision is fixed, it will be very difficult to change. For more details on the IoT and sensors, refer to the AIoT 101 and IoT.exe discussion.
Third: Freeze AIoT System Architecture
The acquisition of an AI platform is not only a technical decision but also encompasses strategic aspects (cloud vs. on premises), sourcing, and procurement. The latter should not be underestimated, especially in larger companies. The often lengthy decision-making processes of technology acquisition/procurement processes can potentially derail an otherwise well planned project schedule.
However, what actually constitutes an AI system architecture? Some key elements are as follows:
- Distributed system architecture: how much processing should be done on the edge, how much in the cloud? How are AI models distributed to the edge, e.g., via OTA? How can AI model performance be monitored at the edge? This is discussed in depth in the AIoT 101, as well as the data/functional viewpoint of the AIoT Product/Solution Design.
- AI system architecture: How is model training and testing organized? How is MLops supported?
- Data pipeline: How are data ingestion, storage, transformation and preparation managed? This is discussed in the Data.exe part.
- AI platform: Finally, should a dedicated AI platform be acquired, which supports collaboration between different stakeholders? This is discussed at the end of this chapter.
Fourth: Acquisition of Training Data
Potentially one of the most resource intensive tasks of an AIoT project is the acquisition of the training data. This is usually an ongoing effort, which starts in the early project phase. Depending on the product category, this task will then either go on until the product design freeze ("first-time-right"), or even continue as an ongoing activity (continuous model improvements). In the context of AIoT, we can identify a number of different product categories. Category I is what we are calling mechanical or electro-mechanical products with no intelligence on board. Category II includes software-defined products where the intelligence is encoded in hand-coded rules or software algorithms. Category III are "first-time-right" products, which cannot be changed or updated after manufacturing. For example, a battery-operated fire alarm might use embedded AI for smoke analysis and fire detection. However, since it is a battery-operated and lightweight product, it does not contain any connectivity, which would be the prerequisite for later product updates, e.g., via OTA. Category IV are connected test fleets. These test fleets are usually used to support generation of additional test data, as well as validation of the results of the model training. A category III product can be created using a category IV test fleet. For example, a manufacturer of fire alarms might produce a test fleet of dozens or even hundreds of fire alarm test systems equipped with connectivity for testing purposes. This test fleet is then used to help finalizing the "first-time-right" version of the fire alarm, which is mass produced without connectivity. Of course, category IV test fleets can also be the starting point for developing an AI which then serves as the starting point for moving into a production environment with connected assets or products in the field. Such a category V system will use the connectivity of the entire fleet to continuously improve the AI and re-deploy updated models using OTA. Such a self-supervised fleet of smart, connected products is the ideal approach. However, due to technical constraints (e.g., battery lifetime) or cost considerations this might not always be possible.
This approach of classifying AIoT product categories was introduced by Marcus Schuster, who heads the embedded AI project at Bosch. It is a helpful tool to discuss requirements and manage expectations of stakeholders from different product categories. The following will look in more detail at two examples.

Example 1: "First-time-right" Fire Alarm
The first example we want to look at is a fire alarm, e.g., used in residential or commercial buildings. A key part of the fire alarm will be a smoke detector. Since smoke detectors usually have to be applied at different parts of the ceiling, one cannot always assume that a power line or even internet connectivity will be available. Especially if they are battery operated, wireless connectivity usually is also not an option, because this would consume too much energy. This means that any AI-enabled smoke detection algorithm will have to be "first-time-right, and implemented on a low-power embedded platform. Sensors used for smoke detection usually include photoelectric and ionization sensors.
In this example, the first product iteration is developed as a proof-of-concept, which helps validate all the assumptions which must be made according to the AIoT magic triangle: sensor selection, distribution architecture, and AI model selection. Once this is stabilized, a data campaign is executed which uses connected smoke sensors in a test lab to create data sets for model training, covering as many different situations as possible. For example, different scenarios covered include real smoke coming from different sources (real fires, or canned smoke detector tester spray), nuisance smoke (e.g., from cooking or smoking), as well as no smoke (ambient).
The data sets from this data campaign are then validated and organized as the foundation for creating the final product, where the training AI algorithm is then put into or onto silicone e.g., using TinyML and an embedded platform, or even by creating a custom ASIC (application-specific integrated circuit). This standardized, "first-time-right" hardware is then embedded into the mass-manufactured smoke detectors. This means that after the Start of Production (SOP), no more changes to the model will be possible, at least not for the current product generation.

Example 2: Continuous Improvement of Driver Assistance Systems
The second example is the development of a driver assistance systems, e.g., to support highly automated driving. Usually, such systems and the situations they have to be able to deal with are an order of magnitude more complex than those of a basic, first-time-right type of product.
Development of the initial models can be well supported by a simulation environment. For example, the simulation environment can simulate different traffic situations, which the driver assistance system will have to be able to handle. For this purpose, the AI is trained in the simulator.
As a next step, a test fleet is created. This can be, for example, a fleet of normal cars, which undergo a retrofit with the required sensors and test equipment. Usually, the vehicles in the test fleet are connected, so that test data can be extracted, and updates can be applied.
Once the system has reached a sufficient level of reliability, it will become part of a production system. From this moment onwards, it will have to perform under real-world conditions. Since a production system usually has many more individual vehicles than a test fleet, the amount of data which can now be captured is enormous. The challenge now is to extract the relevant data segments from this huge data stream which are most relevant for enhancing the model. This can be done, for example, by selecting specific "scenes" from the fleet data which represent particularly relevant real-world situations, which the model has not yet been trained on. A famous case here is the "white truck crossing a road making a U-turn on a bright, sunny day", since such a scenario has once lead to a fatal accident with a [autopilot.
When comparing the "first-time-right" approach with the continuous improvement approach, it is important to notice that the choice of the approach has a fundamental impact on the entire product design, and how it evolves in the long term. A first-time-right fire alarm is a much more basic product than a vehicle autopilot. The former can be trained using a data campaign which probably takes a couple of weeks, while the latter takes an entire product organization with thousands of AI and ML experts and data engineers, millions or cars on the road, and billions of test miles driven. But then also the value creation is hugely different here. This is why it is important for a product manager to understand the nature of this product, and which approach to choose.

The AIoT Data Loop
Getting feedback from the performance of the products in the field and applying this feedback to improve the AI models is key for ensuring that products are perfected over time, and that the models adapt to any potential changes in the environment. For connected products, the updated models can be re-deployed via OTA. For unconnected products, the learning can be applied to the next product generation.
The problem with many AIoT-enabled systems is: how to identify areas for improvement? With physical products used in the field, this can be tricky. Ideally, the edge-based model monitoring will automatically filter out all standard data, and only report "interesting" cases to the backend for further processing. But how can the system decide which cases are interesting? For this, on usually need to find an ingenious approach which often will not be obvious in the first place.
For example, for automated driving, the team could deploy an AI running in so-called shadow mode. This means the human driver is controlling the car, and the AI is running in parallel, making its own decisions but without actually using them to control the car. Every time the AI makes a decision different from the one of the human driver, this could be of interest. Or, let us take our vacuum robot example. The robot could try to capture situations which indicate sub-optimal product performance, e.g., the vacuum being stuck, or even being manually lifted by the homeowner. Another example is leakage detection for pneumatic systems, using sound pattern analysis. Every time the on-site technician is not happy with the system's recommendations, he could make this known to the system, which in turn would capture the relevant data and mark it for further analysis in the back-office.
The processing of the monitoring data which has been identified as relevant will often be a manual or at least semi-manual process. Domain experts will analyze the data and create new scenarios, which need to be taught to the AI. This will result in extensions to existing data sets (or even new data sets), and new labels which represent the new lessons learned. This will then be used as input to the model re-training. After this, the re-trained models can be re-deployed or used for the next product generation.

This means that in the AIoT Data Loop, data really is driving the development process. Marcus Schuster, project lead for embedded AI at Bosch, comments: Data driven development will have the same impact on engineering as the assembly line had on production. Let’s go about it with the necessary passion.
Fifth: Productize the AI Approach
Based on the lessons learned from the Proof-of-Concept, the chose AI approach must now be productized so that it can support real-world deployment. This includes refining the model inputs/outputs, choosing a suitable AI method/algorithm, and aligning the AI model metrics with UX and IoT system requirements.
Model Inputs/Outputs
A key part of the system design is the definition of the model inputs and outputs. These should be defined as early as possible and without any ambiguity. For the inputs, it is important to identify early on which data are realistic to acquire. Especially in an AIoT solution, it might not be possible technically or from a cost point of view to access certain data that would be ideal from an analytics point of view. In the UBI example from above, the obvious choice would be to have access to the driving performance data via sensors embedded in the vehicle. This would either require that the insurance can gain access to existing vehicle data or that a new, UBI-specific appliance be integrated into the vehicle. This is obviously a huge cost factor, and the insurance might look for ways to cutting this, e.g., by requiring its customer to install a UBI app on their smartphones and try to approximate the driving performance from these data instead.
One can easily see that the choice of input data has a huge impact on the model design. In the UBI example, data coming directly from the vehicle will have a completely different quality than data coming from a smartphone, which might not always be in the car, etc. This means that UBI phone app data would require additional layers in the model to determine if the data are actually likely to be valid.
It is also important that all the information needed to determine the model output is observable in the input. For example, if very blurry photos are used for manual labeling, the human labeling agent would not be able to produce meaningful labels, and the model would not be able to learn from it. [1]
Choosing the AI Algorithm
The choice of the AI method/algorithm will have a fundamental impact not only on the quality of the predictions but also on the requirements regarding data acquisition/data availability, data management, AI platforms, and skills and resources. If the AI method is truly at the core of the AIoT initiative, then these factors will have to be designed around the AI methods. However, this might not always be possible. For example, there might be existing restrictions with respect to available skills, or certain data management technologies that will have to be used.
The following table provides an overview of typical applications of AI and the matching AI algorithms. The table is not complete, and the space is constantly evolving. When choosing an AI algorithm, it is important that the decision is not only based on the data science point of view but also simply from a feasibility point of view. An algorithm that provides perfect results but is not feasible (e.g., from the performance point of view) cannot be chosen.

In the context of an AIoT initiative, it should be noted that the processing of IoT-generated sensor data will require specific AI methods/algorithms. This is because sensor data will often be provided in the form of streaming data, typically including a time stamp that makes the data a time series. For this type of data, specific AI/ML methods need to be applied, including data stream clustering, pattern mining, anomaly detection, feature selection, multi-output learning, semi-supervised learning, and novel class detection. [2]
Eric Schmidt, AI Expert at Bosch: "We have to ensure that the reality in the field -- for example the speed at which machine sensor data can be made accessible in a given factory -- is matching the proposed algorithms. We have to match these hard constraints with a working algorithm but also the right infrastructure, e.g., edge vs. batch."
Aligning AI Model Metrics with Requirements and Constraints
There are usually two key model metrics that have the highest impact on user experience and/or IoT system behaviour: model accuracy and prediction times.
Model accuracy has a strong impact on usability and other KPIs. For example, if the UBI model from the example above is too restrictive (i.e., rating drivers as more risk-taking than they actually are), than the insurance might lose customers simply because it is pricing itself out of the market. On the other hand, if the model is too lax, then the insurance might not make enough money to cover future insurance claims.
Eric Schmidt, AI Expert at Bosch: "We currently see that there is an increasing demand in not only having accurate models, but also providing a quantification of the certainty of the model outcome. Such certainty measurements allow -- for example -- for setting thresholds for accepting or rejecting model results"
Similarly, in autonomous driving, if the autonomous vehicle cannot provide a sufficiently accurate analysis of its environment, then this will result (in the worst case) in an unacceptable rate of accidents, or (in the best case) in an unacceptable rate of requests for avoidable full brakes or manual override requests.
Prediction times tell us how long the model needs to actually make a prediction. In the case of the UBI example, this would probably not be critical, since this is likely executed as a monthly batch. In the case of the autonomous driving example, this is extremely critical: if a passing pedestrian is not recognized in (near-) real time, this can be deadly. Another example would be the recognition of a speed limited by an AIoT solution in a manually operated vehicle: if this information is displayed with a huge delay, the user will probably not accept the feature as useful.
Sixth: Release MVP
In the agile community, the MVP (Minimum Viable Product) plays an important role because it helps ensure that the team is delivering a product to the market as early as possible, allows valuable customer feedback and ensures that the product is viable. Modern cloud features and DevOps methods make it much easier to build on the MVP over time and enrich the product step-by-step, always based on real-world customer feedback.
For most AIoT projects, the launch of the MVP is a much "bigger deal" than in a pure software project. This is because any changes to the hardware setup - including sensors for generating data processed by an AI - are much harder to implement. In manufacturing, the term used is SOP (Start of Production). After SOP, changes to the hardware design usually require costly changes to the manufacturing setup. Even worse, changing hardware already deployed in the field requires a costly product recall. So being able to answer the question "What is the MVP of my smart coffee maker, vacuum robot, or electric vehicle" becomes essential.
Jan Bosch is Professor at Chalmers University and Director of the Software Center: If we look at traditional development, I think the way in which you are representing the "When do I freeze what" is spot on. However, there is a caveat. In traditional development, I spend 90% of my energy and time obtaining the first version of the product. So I go from greenfield to first release, and I spend as little as possible afterwards. However, I am seeing many companies which are shifting toward a model that says "How do I get to a V1 of my product with the lowest effort possible?". Say I am spending 10% on the V1, then I can spend 90% on continuously improving the product based on real customer feedback. This is definitely a question of changing the mindset of manufacturing companies.
Continuous improvement of software and AI models can be ensured today using a holistic DevOps approach, which covers all elements of AIoT: code and ML models, edge (via OTA) and cloud. This is discussed in more detail in the AIoT DevOps section.
Managing the evolution of hardware is a complex topic, which is addressed in detail in the Hardware.exe section.
Finally, the actual rollout or Go-to-Market perspective for AIoT-enabled solutions and products is not to be underestimated. This is addressed in the Rollout and Go-to-Market section.
Required Skills and Resources
AI projects require special skills, which must be made available with the required capacity at the required time, as in any other project situation. Therefore, it is important to understand the typical AI-roles and utilize them. Additionally, it is important to understand how the AI team should be structured and how it fits into the overall AIoT organization.
There are potentially three key roles required in the AI team: Data Scientist, ML Engineer, and Data Engineer. The Data Scientist creates deep, new Intellectual Property in a research-centric approach that can potentially require a 3 to 12-month development time or even longer. So the project will have to make a decision regarding how far a Data Science-centric approach is required and feasible, or in how far re-use of existing models would be sufficient. The ML Engineer turns models developed by data scientists into live production systems. They sit at the intersection of software engineering and data science to ensure that raw data from data pipelines are properly fed to the AI models for inference. They also write production-level code and ensure scalability and performance of the system. The Data Engineer creates and manages the data pipeline that is required for training data set creation, as well as feeding the required data to the trained models in the production systems.

Another important question is how the AI team works with the rest of the software organization. The Digital Playbook proposes the adoption of feature teams, which combine all the required skills to implement and deploy a specific feature. On the other hand, especially with a new technology such as AI, it is also important that experts with deep AI and data skills can work together in a team to exchange best practices. Project management has to carefully balance this out.
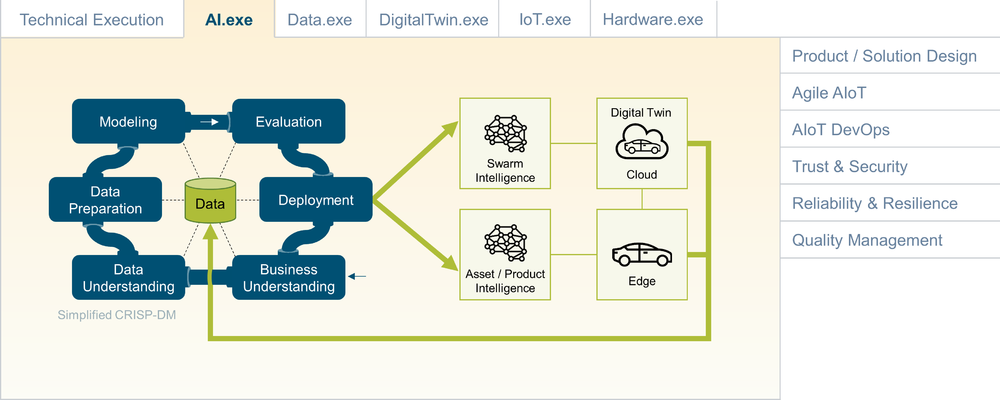
Model Design and Testing
In the case of the development of a completely new model utilizing data science, an iterative approach is typically applied. This will include many iterations of business understanding, data understanding, data preparation, modeling, evaluation/testing, and deployment. In the case of reusing existing models, the model tuning or -- in the case of supervised learning models -- data labeling should also not be underestimated.

Building and Integrating the AI Microservices
A key architectural decision is how to design microservices for inference and business logic. It is considered good practice to separate the inferencing functions from the business logic (in the backend, or -- if deployed on the asset -- also in the edge tier). This means that there should be separate microservices for model input provisioning, AI-based inferencing, and model output processing. While decoupling is generally good practice in software architecture, it is even more important for AI-based services in case specialized hardware is used for inferencing.

Setting Up MLOps
Automating the AI model development process is a key prerequisite not only from an efficiency point of view, but also for ensuring that model development is based on a reproducible approach. Consequently, a new type of DevOps is emerging: MLOps. With the IoT, MLOps not only have to support cloud-based environments but also potentially the deployment and management of AI models on hundreds -- if not hundreds of thousands -- of remote assets. In the Digital Playbook there is a dedicated section on Holistic DevOps for AIoT because this topic is seen as so important.

Managing the AIoT Long Tail: AI Collaboration Platforms
When addressing the long tail of AI-enabled opportunities, it is important to provide a means to rapidly create, test and deploy new solutions. Efficiency and team collaboration are important, as is reuse. This is why a new category of AI collaboration platforms has emerged, which addresses this space. While high-end products on the short tail usually require very individual solutions, the idea here is to standardize a set of tools and processes that can be applied to as many AI-related problems as possible within a larger organization. A shared repository must support the workflow from data management over machine learning to model deployment. Specialized user interfaces must be provided for data engineers, data scientists and ML engineers. Finally, it is also important that the platforms support collaboration between the aforementioned AI specialists and domain experts, who usually know much less about AI and data science.

References
- ↑ The Essential Guide to Creating an AI Product in 2020, Rahul Parundekar, 2020
- ↑ Machine learning for streaming data: state of the art,challenges, and opportunities, H. Gomes et. al., 2020
Authors and Contributors
|



