Data 101
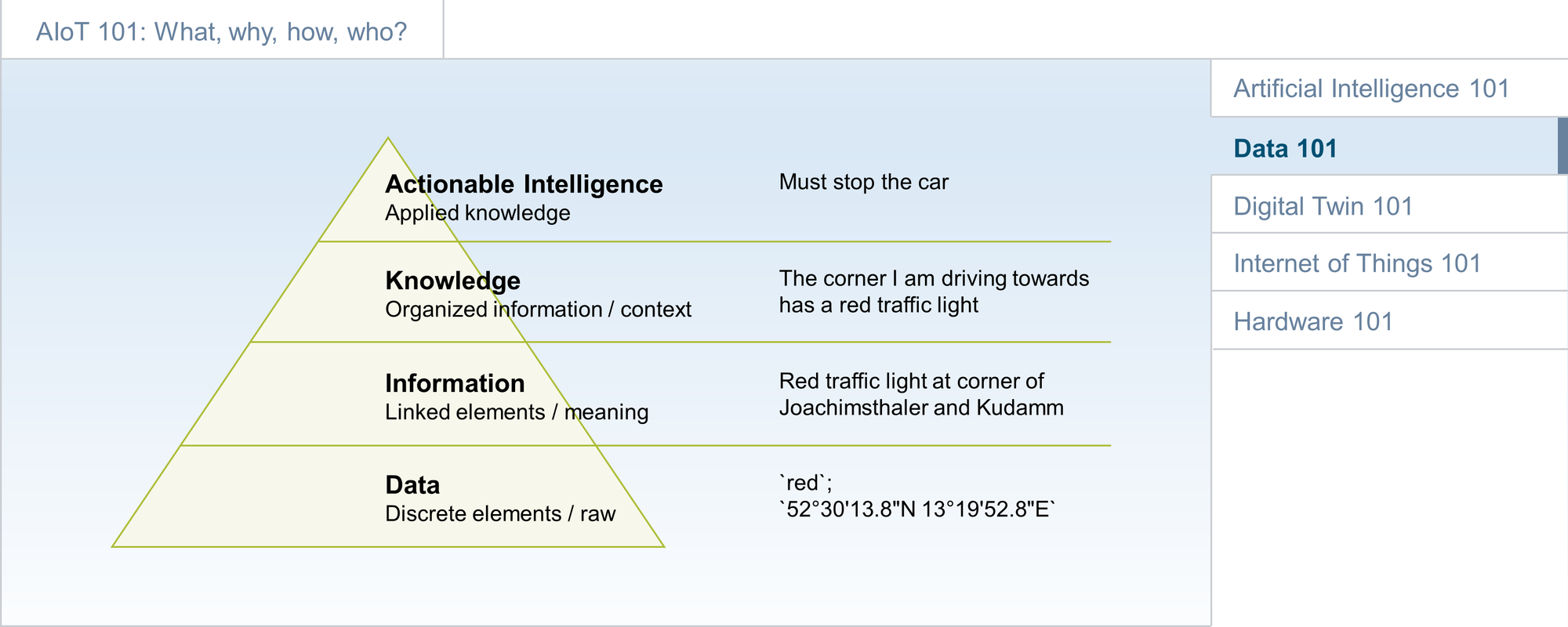
Data are the foundation for almost all digital business models. AIoT adds sensor-generated data to the picture. However, in its rawest form, data are usually not usable. Developers, data engineers, analytics experts, and data scientists are working on creating information from data by linking relevant data elements and giving them meaning. By adding context, knowledge is created [1]. In the case of AIoT, knowledge is the foundation of actionable intelligence.
Data are a complex topic with many facets. Data 101 looks at it through different perspectives, including the enterprise perspective, the Data Management, Data Engineering, Data Science, and Domain Knowledge perspectives, and finally the AIoT perspective. Later, the AIoT Data Strategy section will provide an overview of how to implement this in the context of an AIoT initiative.
Enterprise Data
Traditionally, enterprise data are divided into three main categories: master data, transactional data, and analytics data. Master data are data related to business entities such as customers, products, and financial structures (e.g., cost centers). Master Data Management (MDM) aims to provide a holistic view of all the master data in an enterprise, addressing redundancies and inconsistencies. Transactional data is data related to business events, e.g., the sale of a product or the payment of an invoice. Analytics data are related to business performance, e.g., sales performance of different products in different regions.
From the product perspective, PLM (Product Lifecycle Management) data play an important role. This includes traditionally designed data (including construction models, maintenance instructions, etc.), as well as the generic Engineering Bill of Material (EBOM), and for each product instance a Manufacturing Bill of Material (MBOM).
With AIoT, additional data categories usually play an important role, representing data captured from the assets in the field: asset condition data, asset usage data, asset performance data, and data related to asset maintenance and repair. Assets in this context can be physical products, appliances or equipment. The data can come from interfacing with existing control systems or from additional sensors. AIoT must ensure that these raw data are eventually converted into actionable intelligence.

Data Management
Because of the need to efficiently manage large amounts of data, many different databases and other data management systems have been developed. They differ in many ways, including scalability, performance, reliability, and ability to manage data consistency.
For decades, relational database management systems (RDBMS) were the de facto standard. RDBMS manage data in tabular form, i.e., as a collection of tables with each table consisting of a set of rows and columns. They provide many tools and APIs (application programming interfaces) to query, read, create and manipulate data. Most RDBMS support so-called ACID transactions. ACID relates to Atomicity, Consistency, Isolation, and Durability. ACID transactions guarantee the validity of data even in the case of fatal errors, e.g., an error during a transfer of funds from one account to another. Most RDBMS support the Structure Query Language (SQL) for queries and updates.
With the emergence of so-called NoSQL databases in the 2010s, the quasi-monopoly of the RDBMS/SQL paradigm ended. While RDBMS are still dominant for transactional data, many projects are now relying on alternative or at least additional databases and data management systems for specific purposes. Examples of NoSQL databases include column databases, key-value databases, graph databases, and document databases.
Column (or wide-column) databases group and store data in columns instead of rows. Since they have neither predefined keys nor column names, they are very flexible and allow for storing large amounts of data within a single column. This allows them to scale easily, even across multiple servers. Document-oriented databases store data in documents, which can also be interlinked. They are very flexible because there is no dedicated schema required for the different documents. Also, they make development very efficient since modern programming languages such as JavaScript provide native support for document formats such as JSON. Key-value databases are very simple but also very scalable. They have a dictionary data structure for storing objects with a unique key. Objects are retrieved only via key lookup. Finally, graph databases store complex graphs of objects, supporting very efficient graph operations. They are most suitable for use cases where many graph operations are required, e.g., in a social network.

Analytics Platforms
In addition to the operational systems utilizing the different types of data management systems, analytics was always an important use case. In the 1990s, Data Warehousing systems emerged. They aggregated data from different operational and external systems, and ingested the data via a so-called "Extract/Transform/Load" process. The results were data marts, which were optimized for efficient data analytics, using specialized BI (Business Intelligence) and reporting tools. Most Data Warehousing platforms were very much focused on the relational data model.
In the 2010s, Data Lakes emerged. The basic idea was to aggregate all relevant data in one place, including structured (usually relational), non-structured and semi-structured data. Data lakes can be accessed using a number of different tools, including ML/Data Science tools, as well as more traditional BI/reporting tools.
Data lakes were usually designed for batch processing. Many IoT use cases require near real-time processing of streaming and time series data. A number of specialized tools and stream data management platforms have emerged to support this.
From an AIoT point of view, the goal is to eventually merge big data/batch processing with real-time streaming analytics into a single platform to reduce overheads and minimize redundancies.

Data Engineering
Data are the key ingredient for AI. AI expert Andrew Ng has gone as far as launching a campaign to shift the focus of AI practitioners from focusing on ML model development to the quality of the data they use to train the models. In his presentations, he defines the split of work between data-related activities and actual ML model development as 80:20 - this means that 80% of the time and resources are spent on data sourcing and preparation. Building a data pipeline based on a robust and scalable set of data processing tools and platforms is key for success.

Data Pipeline
From an AIoT point of view, data will play a central role in making products and services 'smart'. In the early stages of the AIoT initiative, the data domain needs to be analysed (see Data Domain Model) to understand the big picture of which data are required/available, and where it resides from a physical/organizational point of view. Depending on the specifics, some aspects of the data domain should also be modeled in more detail to ensure a common understanding. A high-level data architecture should govern how data are collected, stored, integrated, and used. For all data, it must be understood how it can be accessed and secured. A data-centric integration architecture will complete the big picture.
The general setup of the data management for an AIoT initiative will probably differentiate between online and offline use of data. Online relates to data that come from live systems or assets in the field; sometimes also a dedicated test lab. Offline is data (usually data sets) made available to the data engineers and data scientists to create the ML models.
Online work with data will have to follow the usual enterprise rules of data management, including dealing with data storage at scale, data compaction, data retirement, and so on.
The offline work with data (from an ML perspective) usually follows a number of different steps, including data ingestion, data exploration and data preparation. Parallel to all of this, data cataloging, data versioning and lineage, and meta-data management will have to be done.
Data ingestion means the collection of the required data from different sources, including batch data import and data stream ingestion. Typically, this can already include some basic filtering and cleansing. Finally, for data set generation, the data need to be routed to the appropriate data stores.
The ingested data then must be explored. Initial data exploration will focus on the quality of the data and measurements. Data quality can be assessed in several different ways, including frequency counts, descriptive statistics (mean, standard deviation, median), normality (skewness, kurtosis, frequency histograms), etc. Exploratory data analysis helps understand the main characteristics of the data, often using statistical graphics and other data visualization methods.
Based on the findings of the data exploration, the data need to be prepared for further analysis and processing. Data preparation includes data fusion, data cleaning, data augmentation, and finally the creation of the required data sets. Important data cleaning and preparation techniques include basic cleaning ("color" vs. "colour"), entity resolution (determining whether multiple records are referencing the same real-world entity), de-duplication (eliminating redundancies) and imputation. In statistics, imputation describes the process of replacing missing data with substituted values. This is important, because missing data can introduce a substantial amount of bias, make the handling and analysis of the data more arduous, and create reductions in efficiency.
One big caveat regarding data preparation: if the data sets used for AI model training are too much different from the production data against which the models are used later on (inference), there is a danger that the models will not properly work in production. This is why in the figure shown here, automated data preparation occurs online before data extraction for data set creation.

Edge vs. Cloud
In AIoT, a major concern from the data engineering perspective is the distribution of the data flow and data processing logic between edge and cloud. Sensor-based systems that attempt to apply a cloud-only intelligence strategy need to send all data from all sensors to the cloud for processing and analytics. The advantage of this approach is that no data are lost, and the analytics algorithm can be applied to a full set of data. However, the disadvantages are potentially quite severe: massive consumption of bandwidth, storage capacities and power consumption, as well as high latency (with respect to reacting to the analytics results).
This is why most AIoT designs combine edge intelligence with cloud intelligence. On the edge, the sensor data are pre-processed and filtered. This can result in triggers and alerts, e.g., if thresholds are exceeded or critical patterns in the data stream are detected. Local decisions can be made, allowing us to react in near-real time, which is important in critical situations, or where UX is key. Based on the learnings from the edge intelligence, the edge nodes can make selected data available to the cloud. This can include semantically rich events (e.g., an interpretation of the sensor data), as well as selected rich sample data for further processing in the cloud. In the cloud, more advanced analysis (e.g., predictive or prescriptive) can be applied, taking additional context data into consideration.
The benefits are clear: significant reduction in bandwidth, storage capacities and power consumption, plus faster response times. The intelligent edge cloud continuum takes traditional signal chains to a higher level. However, the basic analog signal chain circuit design philosophy should still be taken into consideration. In addition, the combination of cloud/edge and distributed system engineering expertise with a deep domain and application expertise must be ensured for success.

In the example following, an intelligent sensor node is monitoring machine vibration. A threshold has been defined. If this threshold is exceeded, a trigger event will notify the backend, including sample data, to provide more insights into the current situation. This data will allow to analyze the status quo. An important question is: will this be sufficient for root cause analysis? Most likely, the system will also have to store vibration data for a given period of time so that in the event of a threshold breach, some data preceding the event can be provided as well, enabling root cause analysis.

The Big Loop
For some AIoT systems, it can be quite challenging to capture data representing really all possible situations which need to be addressed by the system. This is especially true if the system must deal with very complex and frequently changing environments, and aims to have a high level of accuracy or automation. This is true, for example, for automated driving. In order to deal with the many different, potentially difficult situations such a system has to handle, some companies are implementing what is sometimes called "The big loop": A loop which can constantly capture new, relevant scenarios which the system is not yet able to handle, feed these new scenarios into the machine learning algorithms for re-training, and update the assets in the field with the new models.
Figure 3.9 describes how this can be done for automated driving: The system has an Automated Driving Mode, which gets input from different sensors, e.g. cameras, radar, lidar and microphones. This input is processes via sensor data fusion, and eventually fed to the AI, which uses the data to plan the vehicle`s trajectory. Based on the calculated trajectory, the actuators of the vehicle are instructed, e.g. steering, accelerating and braking. So far so good. In addition, the system has a so-called Shadow Mode. This Shadow Mode is doing pretty much the same calculations as the Automated Driving Mode, except that it is not actually controlling the vehicle. However, the Shadow Mode is smart in that it recognizes situations which can either not be handled by the AI, or where the result is deemed to be sub-optimal - for example, another vehicle is detected too late, leading to a sharp braking process. In this case, the Shadow Mode can capture the related data as a scenario, which it then feeds back to the training system in the cloud. The cloud collects new scenarios representing new, relevant traffic situations, and uses this scenario data to re-train the AI. The re-trained models can then be sent back to the vehicles in the field. Initially, these new models can also be run in the Shadow Mode, to understand how they are performing in the field - without actually having a potentially negative impact on actual drivers, since the Shadow Mode is not interfering with the actual driving process. However, the Shadow Mode can provide valuable feedback about the new model instance, and can help validating their effectiveness. Once this has been assured, the models can be activated and used the real Automated Driving Mode.
Since such an approach with potentially millions of vehicles in the field can help dealing with massive amounts of sensor data and making this data manageable by filtering out only the relevant scenarios, it is also referred to as Big Loop.

Data Science
Data scientists need clean data to build and train predictive models. Of course, ML data can take many different forms, including text (e.g., for auto-correction), audio (e.g., for natural language processing), images (e.g., for optical inspection), video (e.g., for security surveillance), time series data (e.g., electricity metering), event series data (e.g., machine events) and even spatiotemporal data (describing a phenomenon in a particular location and period of time, e.g., for traffic predictions). Many ML use cases require that the raw data be labeled. Labels can provide additional context information for the ML algorithm, e.g., labeling of images (image classification).
The following provides a discussion of AIoT data categories, followed by details on how to derive data sets and label the training data.
Understanding AIoT Data Categories and Matching AI Methods
Understanding the basic AIoT Data Categories and their matching AI Methods is key to AIoT project success. The Digital Playbook defines five main categories, including snapshot data (e.g., from cameras), event series data (e.g., events from industrial assets), basic time series data (e.g., from a single sensor with one dimension), panel data (time series with multiple dimensions from different basic sensors), and complex panel data (time series with multiple dimensions from different, high-resolution sensors).

The table above maps some common AI methods to these different AIoT data types, including AF - Autocorrelation Functions, AR – Autoregressive Model, ARIMA – ARMA without stationary condition, ARMA – Mixed Autoregressive Mixed Autoregressive –Moving Average Models, BDM - Basic Deterministic Models, CNN – Convolutional Neural Network, FFNN – Feedforward Neural Network, GRU – Gated recurrent unit, HMM – Hidden Markov Models, LSTM – Long short-term memory, MA – Moving Average, OLS – Ordinary Least Squares, RNN – Recurrent Neural Network, SVM – Support Vector Machine.
Data Sets
In ML projects, we need data sets to train and test the model. A data set is a collection of data, e.g., a set of files or a specific table in a database. For the latter, the rows in the table correspond to members of the data set, while every column of the table represents a particular variable.
The data set is usually split into training (approx. 60%), validation (approx. 20%), and test data sets (approx. 20%). Validation sets are used to select and tune the final ML model by estimating the skill of the tuned model for comparison with other models. Finally, the training data set is used to train a model. The test data set is used to evaluate how well the model was trained.

In the article "From model-centric to data-centric"[2], Fabiana Clemente provides the following guiding questions regarding data preparation:
- Is the data complete?
- Is the data relevant for the use case?
- If labels are available, are they consistent?
- Is the presence of bias impacting the performance?
- Do I have enough data?
In order to succeed in the adoption of a data-centric approach to ML, focusing on these questions will be key.
Data Labeling
Data labeling is required for supervised learning. It usually means that human data labellers manually review training data sets, tagging relevant data with specific labels. For example, this can mean manually reviewing pictures and tagging objects in them, such as cars, people, and traffic signs. A data labeling platform can help to support and streamline the process.
Is data labeling the job of a data scientist? Most likely, not directly. However, the data scientist has to be involved to ensure that the process is set up properly, including the relevant QA processes to avoid bad label data quality or labeled data with a strong bias. Depending on the task at hand, data labeling can be done in-house, outhouse, or by crowdsourcing. This will heavily depend on the data volumes as well as the required skill set. For example, correct labeling of data related to medical diagnostics, building inspection or manufacturing product quality will require input from highly skilled experts.

Take, for example, building inspection using data generated from drone-based building scans. This is actually described in detail in the TÜV SÜD building façade inspection case study. Indicators detected in such an application can vary widely, depending on the many different materials and components used for building façades. Large building inspection companies such as TÜV SÜD have many experts for the different combinations of materials and failure categories. Building up a training data set with labeled data for automatically detecting all possible defects requires considerable resources. Such projects typically implement a hybrid solution that combines AI-based automation where there are sufficient training data and manual labeling where there is not. The system will first attempt to automatically detect defects, allowing false positives and minimizing false negatives. The data is then submitted for manual verification. Depending on the expert’s opinion the result is accepted or replaced with manual input. The results of this process are then used to further enhance the training dataset and create the problem report for the customer. This example shows a type of labeling process that will require close collaboration between data engineers, data scientists and domain experts.
Domain Knowledge
One of the biggest challenges in many AI/ML projects is access to the required domain knowledge. Domain knowledge is usually a combination of general business acumen, industry vertical knowledge, and an understanding of the data lineage. Domain knowledge is essential for creating the right hypotheses that data science can then either prove or disprove. It is also important for interpreting the results of the analyses and modeling work.
One of the most challenging parts of machine learning is feature engineering. Understanding domain-specific variables and how they relate to particular outcomes is key for this. Without a certain level of domain knowledge, it will be difficult to direct the data exploration and support the feature engineering process. Even after the features are generated, it is important to understand the relationships between different variables to effectively perform plausibility checks. Being able to look at the outcome of a model to determine if the result makes sense will be difficult without domain knowledge, which will make quality assurance very difficult.
There have been many discussions about how much domain knowledge the data scientist itself needs, and how much can come from domain experts in the field. The general consensus seems to be that a certain amount of domain knowledge by the data scientist is required and that a team effort where generalist data scientists work together with experienced domain experts usually also works well. This will also heavily depend on the industry. An internet start-up that is all about "clicks" and related concepts will make it easy for data scientists to build domain knowledge. In other industries, such as finance, healthcare or manufacturing, this can be more difficult.
The case study AIoT in High-Volume Manufacturing Network describes how an organization is set up which always aims to team up data science experts with domain experts in factories (referred to as "tandem teams"). Another trend here is "Citizen Data Science", which aims to make it easy to use data science tools available directly to domain experts.
In many projects, close alignment between the data science experts and the domain experts is also a prerequisite for trust in the project outcomes. Given that it is often difficult in data science to make the results "explainable", this level of trust is key.
Chicken vs. Egg
Finally, a key question for AIoT initiatives is: what comes first, the data or the use case? In theory, any kind of data can be acquired via additional sensors to best support a given use case. In practice, the ability to add more sensors or other data sources is limited due to cost and other considerations. Usually, only greenfield, short tail AIoT initiatives will have the luxury of defining which data to use specifically for their use case. Most long tail AIoT initiatives will have to implement use cases based on already existing data.
For example, the building inspection use case from earlier is a potential short tail opportunity, which will allow the system designers to specify exactly which sensors to deploy on the drone used for the building scans, derived from the use cases which need to be supported. This type of luxury will not be available in many long tail use cases, e.g., in manufacturing optimization as outlined in AIoT and high volume manufacturing case study.

References
- ↑ Conceptual Approaches for Defining Data, Information, and Knowledge, Zins, Chaim, 2007, Journal of the American Society for Information Science and Technology.
- ↑ From model-centric to data-centric, Fabiana Clemente, 2021, https://towardsdatascience.com/from-model-centric-to-data-centric-4beb8ef50475